次回マルレクは、5月31日 KDDIさんで開催です
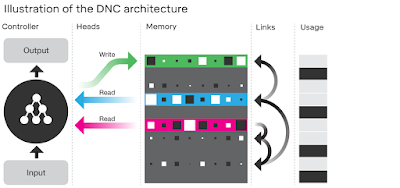
次の要領で次回のマルレクを開催します。 日 時:5月31日 19:00-21:00 場 所:KDDI本社会議室(飯田橋) 定 員:150名 参加費:1,000円(個人協賛会員は無料です) 申 込:個人協賛会員 5月17日 12:00から 一般 5月24日 12:00から 講 師:丸山不二夫 テーマ:「ニューラル・コンピュータとは何か?」 概 要: 現在のニューラル・ネットワークのモデルは、基本的には、次の三種類です。 ・DNN (Deep Neural Network: Full Connect Perceptron ) ・CNN (Convolutional Neural Network ) ・RNN (Recurrent Neural Network ) ここにきて、第四のモデルとしての「ニューラル・コンピュータ」に注目が集まっています。 それは、画像認識が得意なCNNや、自然言語処理のようなSequence to Sequenceの処理が得意なRNNのように、特定の課題にフォーカスしたモデルではなく、むしろ、外部メモリーを活用する現在のコンピュータのアーキテクチャーそのものを、ディープ・ラーニング技術の知見を生かして拡張しようとする意欲的なものです。 興味深いのは、そのアーキテクチャーが挑戦している課題は、上記の三つのモデルでは解くのが難しかった、ヒューリスティックな、あるいは、論理的な「推論」を機械に実行させることです。 講演では、GoogleのDeepMind チームがNatureに公開した論文の解説を行います。 次の資料を参照ください。 「可微分ニューラルコンピュータとは何か(1) 概論」 http://maruyama097.blogspot.com/2017/03/blog-post_17.html 「可微分ニューラルコンピュータとは何か(2) システム概観」 http://maruyama097.blogspot.com/2017/03/blog-post_18.html

