20数年前、いったん放棄されたRNN
テキストの文字列や音素のつらなりである人間の発話、あるいは音楽の音やビデオのフレームのようなSequentialなデータは、我々の周りに多数存在している。こうしたSequentialなデータを、単純なニューラル・ネットを横に連ねたニューラル・ネットで解析しようとするRNNは、当初、大きな関心を集めたようだ。今から、20数年前のことだ。
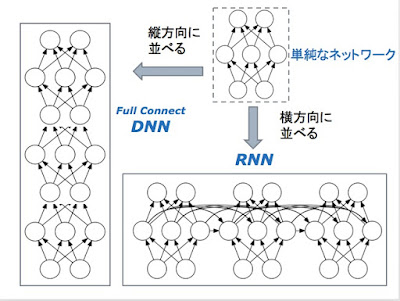


Full ConnectのDNNでは、各層ごとの重みのパラメーター Wi は、一般には、異なっている。RNNでは、隠れ層を結ぶ重みのパラメーター W は、常に同じである。DNNの場合には、勾配の消失が起きそうになったら、一つ一つの層の「学習率」を個別に修正して、問題に対応できる。これは、いささか姑息な手段だが、DNNでは有効である。しかし、この方法は、常に全く同じ形でパラメーターを適用するRNNには、適用できない。
さらに、一般的には、DNNでの縦への積み重ねより、RNNでの横の繰り返しは長くなる傾向がある。50段重ねのDNNは、あまり見たことないが、50文字以上の文字列を扱うRNNを作ろうとするのは自然である。
20数年前、皆さんいろいろやって見たらしいが、実験結果は、思わしくなかった。
そこにある論文が登場する。1994年、Bengioらが、"Learning Long-Term Dependencies with Gradient Descent is Difficult" という論文を発表する。この論文は、長いRNNでの学習の難しさを、理論的に証明したものだった。実は、それより早く、1991年に、Hochreiter がドイツ語で書いた修士論文で、同じ証明を与えていたことが、現在では知られている。
これらの論文で、RNNの学習の困難の理論的根拠が明らかにされたことを受けて、当時のニューラルネットの世界では、RNNの探求は、事実上、放棄されることになったらしい。
次のポストで、DNNの復活の動きを紹介しようと思う。

隠れ層をつなぐ接続を同じ重みのパラメーター W を共有し、同一のネットワークを繰り返し利用するというアイデアで、実装の負担も抑えられそうに見えた。
ところが、この試みはうまくいかなかった。RNNでは、Back Propargation / Gradient Descent を使った学習アルゴリズムがうまく働かないのだ。横に並ぶネットワークの数が増えるにつれて、パラメーターを修正する勾配が、どんどんゼロに近づいてゆくのだ(時には、爆発的に増大することもあった)。「勾配の消失(あるいは、爆発)の問題」という。
当時のRNNは、次のような形をしていたらしい。 (この繰り返し)

この式に問題があったわけではない。この構成のRNNは、繰り返しの少ない短い系列なら、ちゃんと動くのだ。問題は、他のところにあった。
Full ConnectのDNNとRNNとでは、単純なニューラルネットを、縦に並べる、横に並べるだけではない違いがある。

さらに、一般的には、DNNでの縦への積み重ねより、RNNでの横の繰り返しは長くなる傾向がある。50段重ねのDNNは、あまり見たことないが、50文字以上の文字列を扱うRNNを作ろうとするのは自然である。
20数年前、皆さんいろいろやって見たらしいが、実験結果は、思わしくなかった。
そこにある論文が登場する。1994年、Bengioらが、"Learning Long-Term Dependencies with Gradient Descent is Difficult" という論文を発表する。この論文は、長いRNNでの学習の難しさを、理論的に証明したものだった。実は、それより早く、1991年に、Hochreiter がドイツ語で書いた修士論文で、同じ証明を与えていたことが、現在では知られている。
これらの論文で、RNNの学習の困難の理論的根拠が明らかにされたことを受けて、当時のニューラルネットの世界では、RNNの探求は、事実上、放棄されることになったらしい。
次のポストで、DNNの復活の動きを紹介しようと思う。

コメント
コメントを投稿